SPEED: Thorough and honest appraisal of AI for neonatal seizure detection
February 26, 2024
by Robert Hogan
AI research
Over the past two decades, strides have been made in automated neonatal seizure detection using AI. The progression extends from simple heuristics to early machine learning systems and, more recently, the application of advanced deep learning techniques, resulting in a steady improvement in reported performance.
Despite this, there remains a challenge in translating performance benchmarks from research papers into something that can be understood and trusted by clinicians. Some examples of detailed studies (e.g., ANSeR algorithm validation from INFANT¹) have been encouraging. Still, in many cases, the clinical relevance of the performance metrics improvements is unclear.
Today, we are open-sourcing SPEED (Seizure Prediction Evaluation for EEG-based Detectors) as a first step to building community interest in solving this problem. SPEED addresses three key common limitations on the current evaluations in literature:
Standardised metric calculation making results comparable
Multiple diverse metrics, including sample, event, and baby-based versions - removing reliance on just one or two commonly reported metrics
Inclusion of clinically relevant measures
What’s wrong with the metrics we have?
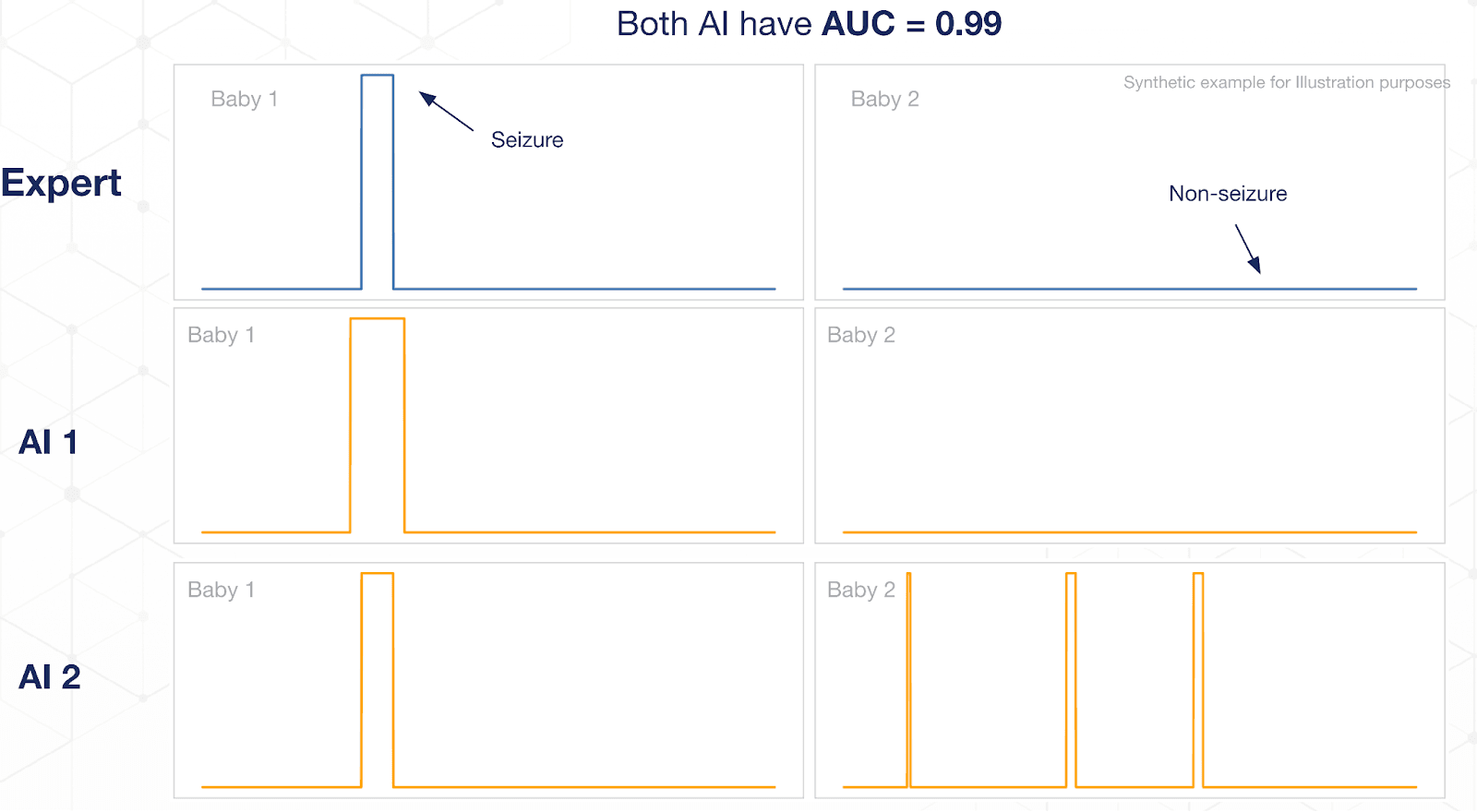
The most commonly reported metric is AUC (Area Under the receiver-operator Curve), calculated on a per sample basis across the entire dataset. People like this metric because it is insensitive to the classification threshold and gives a sense of how easily you can trade-off Sensitivity and Specificity depending on the clinical need. It’s also easy to compute and to compare algorithms with. But it’s not without its problems:
Seizures are rare, so the dataset is often very imbalanced, which can lead to misleadingly high AUC numbers (see image below)
Treats each sample as equally important, which is not true clinically - finding a single isolated seizure in a baby is more important than finding a similar seizure from a baby with many long duration seizures that have already been detected.
What does SPEED give me?
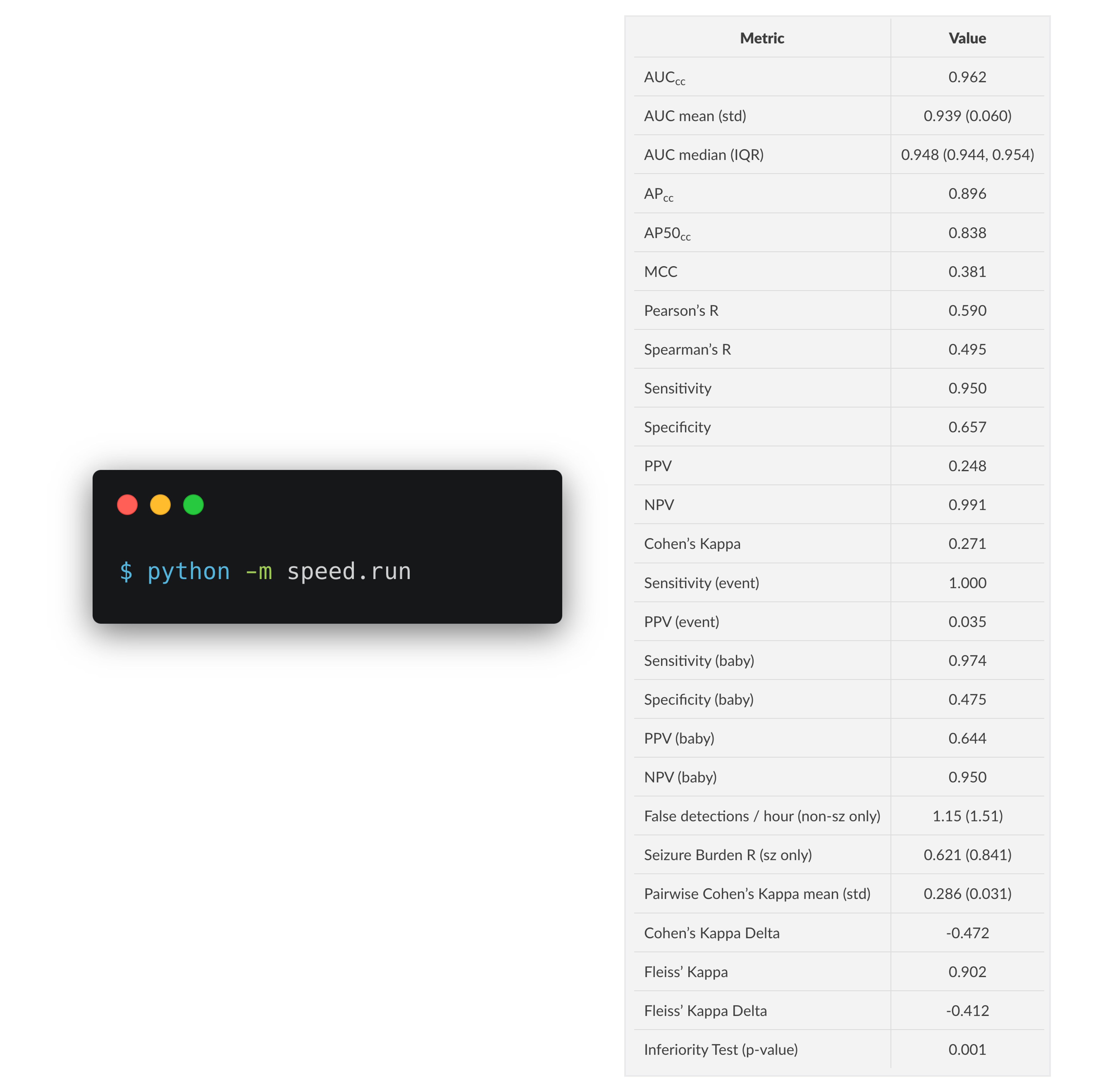
Using the open-source neonatal seizure database from Helsinki², you can simply provide the predictions from your model and run a single command to get a markdown table of metrics. These metrics include clinically relevant metrics like seizure burden estimation, false detection per hour, and measures of (non-)inferiority to human expert raters.
Another command will generate some useful visualisations:
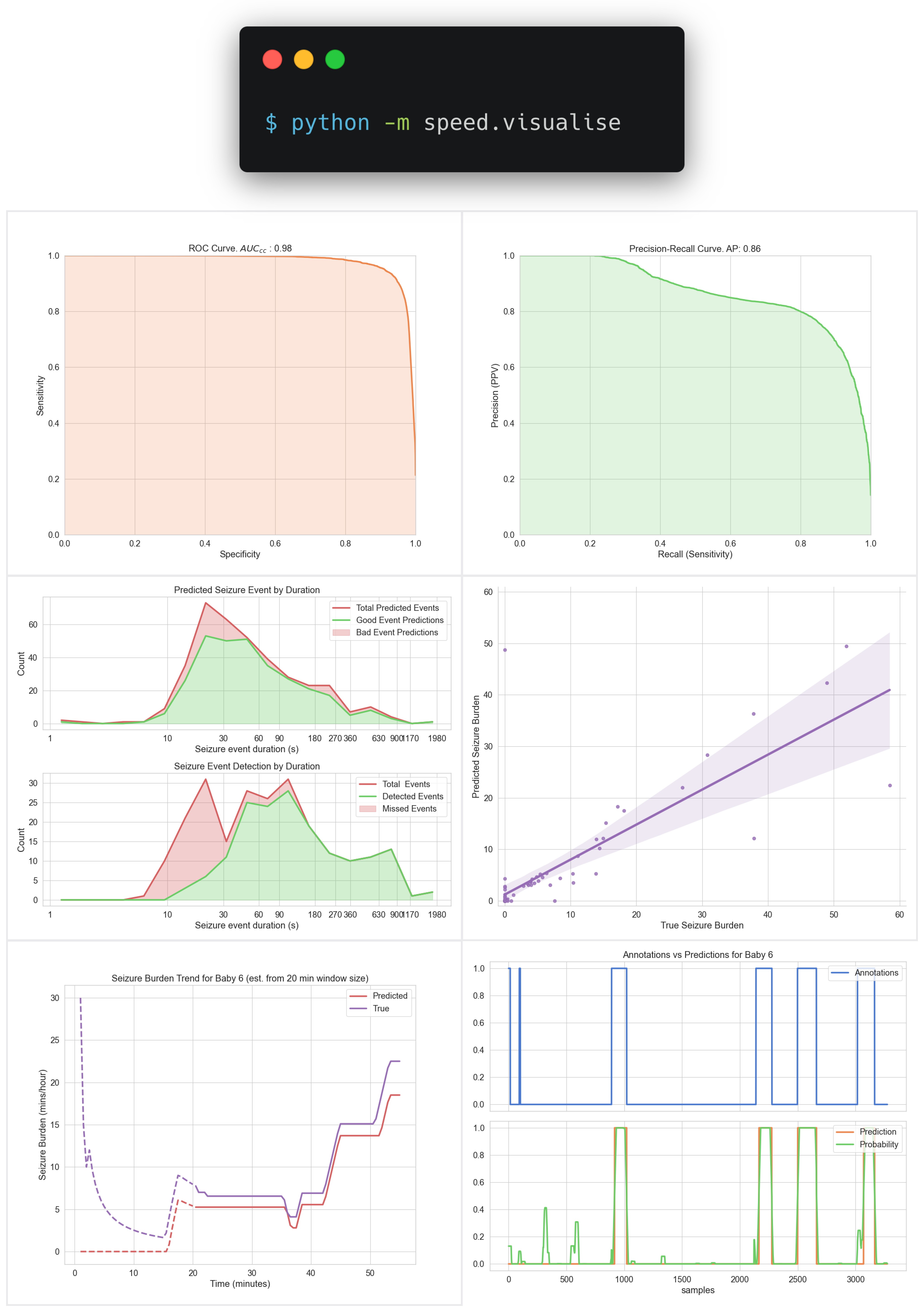
SPEED makes it trivial for researchers to produce detailed evaluations of their latest AI research and make fair comparisons to other published works. It will also allow the community to highlight areas of weakness in these models that have been previously obscured by limited metrics.
What’s next?
This is just a first step. We hope to add more evaluations, visualisations, and datasets in future. We welcome contributions from the community, in particular we would love to hear from clinicians on what they would like to understand about seizure detection models for use in their practice.
¹Pavel AM et al. “A machine-learning algorithm for neonatal seizure recognition: a multicentre, randomised, controlled trial”. The Lancet Child & Adolescent Health. 2020 Oct 1;4(10):740-9. ²Stevenson, N et al. “A dataset of neonatal EEG recordings with seizure annotations”. Sci Data 6, 190039 (2019)